Overview
LLMs have opened new possibilities of automated agents that plan and complete tasks on the user’s behalf. Such agents have the potential to usher in a new industrial revolution by automating organizational processes. However, agents are currently limited to soft-edge tasks that have large tolerances for error, and are too unreliable for hard-edge tasks, like in healthcare or enterprises, where accuracy and reliability are paramount. In short, what does it take for agents to be used in enterprises?
This graduate-level course will cut across the technology stack to examine the research questions that need to be answered for agents to be possible in real tasks that matter. Each session will review 1-3 papers or systems, and discuss research opportunities that arise from the gap between existing research and enterprise requirements. Topics will span systems (data systems and ML systems), AI (LLMs, agent-based planning), HCI, and theory (reinforcement learning, markets).
Broad questions include
- What mechanisms are data systems missing to support agents?
- How does human-computer interaction change when the human interacts with agents?
- How can knowledge throughout an organization be used to constrain and improve agentic planning?
- How can systems handle the 10-100x increase in load generated by agents?
- What are the theoretical limits of what agents can do?
- At scale, how will the use of agents affect markets, incentives, and the structure of organizations?
Class Structure
- There will be assigned readings for each week
- Classes will be a mix of discussion about the papers, speculating about new problems, and external speakers
- Due to the speculative nature of the course, students are expected to co-investigate the problems alongside the instructors.
Project ideas
For 6113 Students Only: Google doc with suggestions. You are welcome to add your own ideas!
Tentative Schedule
1/21 Introduction & a quick history of agents - Eugene & Kostis
1/23 Tutorial: Agents Overview - Xiao Yu, Columbia
-
Toggle Bio
I am a second year Ph.D. student in Computer Science at Columbia University advised by Zhou Yu. Before joining the Ph.D. program, I was an undergrad also at Columbia University, majoring in Computer Science and minoring in Applied Physics. Currently I am interested in: 1) Reinforcement Learning + (V)LM Training, and 2) Planning Algorithms + (V)LM Agents. My recent works include developing search algorithms to improve (V)LM's performance on dialogue tasks such as persuasion and agentic tasks such as using a web browser or a virtual machine; and methods to train (V)LMs without extensive human labeling efforts.
- Readings
- Questions
- What are some real life applications that can make use of/benefit from these computer agents?
- What are some concerns/limitations?
1/28 Tutorial: Agent Planning - Xiao Yu, Columbia
- Readings
- Questions
- What other tasks/domains would benefit from these self-learning/planning approaches?
- What key limitations or errors should you watch for when using these approaches?
01/30 Background: SWEBench - John Yang, Stanford
-
Toggle Bio
John Yang is a PhD student at Stanford University advised by Prof. Diyi Yang and Ludwig Schmidt. He formerly conducted research at Princeton University advised Prof. Karthik Narasimhan. John works on evaluations, data, and systems around Language Model (LM) agents for software engineering
- Readings
- Questions
- What might the future of evaluations for Language Models and AI Systems look like? Can you think of any real world workflows or pipelines (not necessarily within Software Engineering or Tech) that might be interesting testbeds?
- How might AI agents be deployed in a real world? How might the responsibilities of a software developer / manager and the technology market itself evolve in response to AI co-pilots?
02/04 Programming Foundation Models Thomas Joshi, Columbia
-
Toggle Bio
Thomas Joshi is co-author of Stanford DSPy and leads the GenAI Collective, the largest AI community in the US with over 30,000 members across chapters in SF, NYC, Boston, London, Paris, and other cities. DSPy has been used by Nvidia, Microsoft, Meta, NASDAQ, Carlyle, ABN Amro, JetBlue, Cohere, and others. Thomas is passionate about modular approaches to AI system design, enabling engineers to optimize LLM pipelines for performance and cost-efficiency.
- Readings
- Questions (rather than answering these, use the questions as a starting point for discussion on slack)
- Modular frameworks like DSPy enhance flexibility and scalability in agentic systems but may introduce inefficiencies due to communication overhead between modules. How do these trade-offs affect the performance of agents in real-world applications? What strategies could be used to minimize these inefficiencies while retaining the advantages of modularity?
- DSPy’s modular agents use predefined components tailored to specific tasks, but dynamic environments often demand adaptability. How can agents built with modular frameworks autonomously adapt or reconfigure their modules to address unforeseen challenges? What are the current limitations of modular designs in this context, and how could future advancements improve their adaptability?
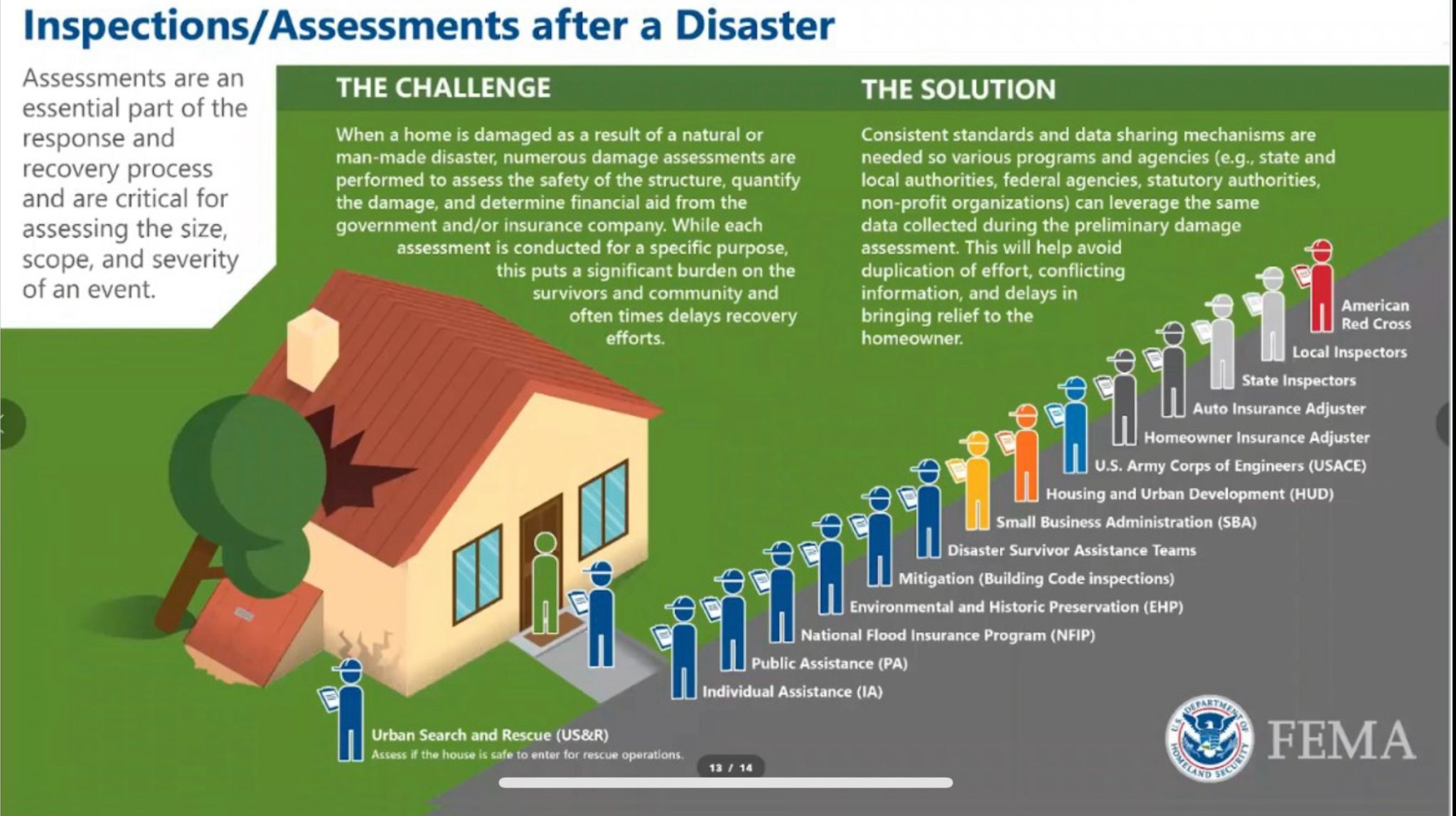
02/06 Use Case: Navigating US Disaster Recovery Bureaucracy - Jeffrey Schlegelmilch, National Center for Disaster Preparedness
-
Toggle Bio
Jeff Schlegelmilch is the Director of the National Center for Disaster Preparedness at the Columbia Climate School, as well as the Director of Executive Education and Non-Degree Programs for the Columbia Climate School. He is also an Associate Professor for Professional Practice in Climate. His areas of expertise include public health preparedness, community resilience, and the integration of private and public sector capabilities.
- Readings
- Questions (use the question as a starting point for discussion on slack)
- In the absence of wholesale change, how can technology support improving efficiency in the bureaucracy of disaster recovery?
02/11 No Lecture: Project Proposal Submission - Instructors will be around to discuss and provide feedback
02/13 Use Case: Agents in Systems Optimization - Shreya Shankar PhD, UC Berkeley
-
Toggle Bio
Shreya Shankar is a PhD student in computer science at UC Berkeley, advised by Dr. Aditya Parameswaran. Her research creates practical tools and frameworks that help people build reliable ML systems, with recent work on declarative interfaces and optimization for unstructured data analysis. Her work appears in top data management and HCI venues like SIGMOD, VLDB, CIDR, CSCW and UIST, and she co-organizes the DEEM workshop at SIGMOD. She is supported by the NDSEG Fellowship. Prior to Berkeley, she worked as an ML engineer after completing her B.S. in computer science at Stanford University. In her free time, she enjoys roasting coffee and is actively trying to reduce her Twitter usage.
- Readings
- DocETL
- Palimpzest (cost optimization for LLM-powered data processing)
- (Optional) ELEET (fine-tuning smaller models for optimized query execution)
- Questions (rather than answering these, use the questions as a starting point for discussion on slack)
- Systems: These systems represent different philosophies about determinism in data processing, both in optimization and execution stages: ELEET aims for deterministic extraction with small models, Palimpzest provides deterministic optimization with non-deterministic execution, and DocETL embraces non-determinism in both optimization (given the agents) and execution. How should we think about reliability and correctness guarantees in these different paradigms?
- Systems: These systems take different approaches to balancing accuracy vs. cost - DocETL optimizes for accuracy with LLM agents, ELEET uses smaller targeted models, and Palimpzest focuses on cost-effective model orchestration. What engineering principles should guide choosing between these approaches for different use cases? What might a unified framework look like?
- HCI: In document processing systems like DocETL, LLMs can fail in inconsistent ways - e.g., a single LLM may correctly extract 8 names but miss 2 others from the same document, but extract names from other documents perfectly. Unlike traditional data processing errors that follow patterns (e.g., failing on malformed input), LLM failures seem random and hard to systematize. How should interfaces help users validate results and develop trust, when the underlying operations have this fundamentally unpredictable behavior?
02/18 Background: Agent Frameworks - Phil Calçado, Outropy
- Readings:
- Questions (think about and discuss one or more of these topics on slack))
- Looking at past transformative technologies like the early internet or mobile applications, we see initial barriers around cost, latency, and complexity—challenges that parallel those of today’s AI agents. What key engineering and scientific breakthroughs enabled these technologies to become practical at scale, and what lessons can we apply to AI agents today?
- Modern cloud architectures are built around stateless, horizontally scalable services, yet AI agents rely on maintaining context and memory. How can these opposing principles be reconciled when designing scalable AI systems? What emerging architectural patterns might enable both scalability and statefulness?
- The shift from monolithic models to Compound AI systems—where multiple specialized AI components work together—suggests that system design and integration are becoming as crucial as model capabilities. How does this change the skills required for AI engineering, and what new challenges arise when optimizing multi-agent AI systems?
02/20 Background: Foundation Models for Embodied/Physical Agents - Yunzhu Li, Columbia
-
Toggle Bio
I am an Assistant Professor of Computer Science at Columbia University. Before joining Columbia, I was an Assistant Professor at UIUC CS. I also spent time as a Postdoc at the Stanford Vision and Learning Lab (SVL), working with Fei-Fei Li and Jiajun Wu. I received my PhD from the Computer Science and Artificial Intelligence Laboratory (CSAIL) at MIT, where I was advised by Antonio Torralba and Russ Tedrake, and I obtained my bachelor's degree from Peking University.
Foundation models, such as GPT-4 Vision, have marked significant achievements in the fields of natural language and vision, demonstrating exceptional abilities to adapt to new tasks and scenarios. However, physical/embodied interaction—such as cooking, cleaning, or caregiving—remains a frontier where foundation models and robotic systems have yet to achieve the desired level of adaptability and generalization.
In this talk, I will discuss the opportunities for incorporating foundation models into classic robotic pipelines to endow robots/physical agents with capabilities beyond those achievable with traditional robotic tools. The talk will focus on three key improvements in (1) task specification, (2) low-level, and (3) high-level scene modeling. The central idea behind this research is to translate the commonsense knowledge embedded in foundation models into structural priors that can be integrated into robot learning systems. This approach leverages the strengths of different modules (e.g., VLM for task interpretation and constrained optimization for motion planning), achieving the best of both worlds. I will demonstrate how such integration enables robots to interpret instructions provided in free-form natural language, and how foundation models can be augmented with additional memory mechanisms, such as an action-conditioned scene graph, to handle a wide range of real-world manipulation tasks.
Toward the end of the talk, I will discuss the limitations of the current foundation models, challenges that still lie ahead, and potential avenues to address these challenges
- Readings
- https://voxposer.github.io/
- https://rekep-robot.github.io/
- Questions
- You’ve already seen numerous practical applications of AI agents powered by foundation models in virtual environments. What do you see as the key opportunities and challenges in extending these capabilities to physical agents, particularly those that interact with the real world through robotic manipulation?
- Additionally, how do the key considerations and assumptions differ between virtual and physical settings?
02/25 Agent-Ready Systems - Jerry/Nikos/Peter/Eugene/Kostis, Columbia
- Readings
- See class Slack for paper
- Questions
- What makes agents different from previous workloads/applications from a systems perspective?
- Based on what we have seen this semester, other systems capabilities may be useful for agent-ready systems to support?
02/27 Systems: Lineage and Data-flow policies - Eugene Wu, Columbia
- Readings
- Questions
- How is provenance useful in the context of agents?
03/04 Human-Agent Interaction. Lydia Chilton
- Readings:
- Questions
- When is human intervention necessary or beneficial in agent-based systems?
03/06 Models: Neurosymbolic training - Baishakhi Ray, Columbia
- Readings
- SemCoder
- C2SAFERRUST
- Questions to ponder and discuss at least the day before the class!! (e.g., not 10 minutes before class)
- How neuro-symbolic training can help?
- What is the purpose of neurosymbolic reasoning in agentic workflow?
03/11 Human data for building agents that model our minds - Danielle Perszyk, Amazon
-
Toggle Bio
Danielle Perszyk is a cognitive scientist at the Amazon AGI SF Lab leading the human data collection efforts for building agents. She received her PhD from Northwestern, where she studied the developmental and evolutionary origins of human's link between language and thought. Previously, she built human data collection programs for UX research and AI model training at Google and Adept.
- Readings
- Question to discuss at least the day before class!
- What does it mean for an agent to model (understand) human minds?
03/13 No Class! Attend the Agents for Work workshop on 3/12 (link in slack)
03/25 Agent Planning: RL and MCTS - Shipra Agrawal, Columbia
- Readings
- Questions to ponder while reading. Discuss these at least one day BEFORE class!
- How can we combine reinforcement learning methods (like Q-learning) with planning and search to achieve strong performance under small search budgets?
- What is the role of planning (vs. learning) in performance of agents? What can we learn from the studies of similar approaches for RL systems such as MuZero? Which insights transfer to Agentic systems and which don’t?
03/27 Use Case: Financial Products - Raman Jatkar, Intellect Design
- Readings
- Questions to ponder while reading. Discuss these at least one day BEFORE class!
- What change management approaches are essential for successful Agent systems adoption in financial institutions?
- Identify real-world applications of multi-agent systems in financial services - in banking, insurance, and wealth management.
- What key performance indicators should be used to evaluate the effectiveness of agentic systems in enterprise operations?
04/01 HAI: Process Mining and Agents - Wil van der Aalst (the father of process mining), RWTH Aachen University
- Readings
- Questions to ponder
- Consider the following traces in a simplified case-centric event log (each letter refers to an activity and each row refers to a case).
A case could represent the treatment of a patient, the production of a car, or the handling of an invoice. To minimize notation, we use just letters for individual activities. Note that each case starts with activity “a” (e.g., “register patient”) and ends with activity “h” (e.g., “invoice patient”). Assume that all shown traces are frequent (e.g., occur at least 10 times). What process model would you like your discovery technique to discover? Use a Petri net, BPMN model, process tree, or DFG to describe the underlying process.
abcdefgh
abecfgdh
abecfdgh
aebcdfgh
aebcfgdh
abcedfgh
abecdfgh
aebcfdgh
abcefgdh
abcefdgh
...
04/03 Use Case: Coding (AutoCodeRover) - Yuntong Zhang, NUS
-
Toggle Bio
Yuntong Zhang is a fourth-year PhD student at the National University of Singapore, advised by Prof. Abhik Roychoudhury. His research focuses on LLMs for software engineering, particularly the intersection of program analysis and LLMs for automatic programming. Through his work on the LLM agent AutoCodeRover, he co-founded a spin-off on AI-based coding, which was later acquired by SonarSource.
- Readings
- Questions to ponder while reading. Discuss these at least one day BEFORE class!
- What strategies can be employed to improve the acceptability and trustworthiness of code generated by LLM agents?
04/08 Opportunities and Challenges in Building Agentic Products for Commerce - Shankar Bhargava, WalmartLabs
- Readings
- Questions to ponder
- How are agentic systems changing how people search? Has your own usage of Google changed in the past year. How do you think this will change how people shop?
- Based on what you have learnt in this course so far, what do you think are the challenges in building reliable agentic products for consumers? What are some good metrics to evaluate a consumer shopping agent or assistant?
04/10 The second half - Shunyu Yao, OpenAI
-
Toggle Bio
Shunyu Yao is a researcher at OpenAI. Previously, he finished his PhD from Princeton. He co-invented some of the most influential and widely used agent methods (ReAct, Tree of Thoughts, Reflexion) and benchmarks (WebShop, SWE-bench, tau-bench), along with OpenAI’s first two agent products (Operator, deep research).
- Readings
- Questions to ponder while reading. Discuss these at least one day BEFORE class!
- In your opinion, what should be the main benchmark to reflect AI’s progress?
04/15 Text2SQL: Compound AI Systems for Querying Structured Data - Fatma Ozcan, Google Research
-
Toggle Bio
Fatma Ozcan is a Principal Engineer at Systems Research@Google. Before that, she was a Distinguished Research Staff Member and a senior manager at IBM Almaden Research Center. Her current research focuses on LLMs and ML for data management, text2SQL and conversational interfaces to data, platforms and infrastructure for large-scale data analysis. Dr Ozcan got her PhD degree in computer science from University of Maryland, College Park. She has over 23 years of experience in industrial research, and has delivered core technologies into various IBM products. She has been a contributor to various SQL standards, including SQL/XML, SQL/JSON and SQL/PTF. She is the co-author of the book Heterogeneous Agent Systems, and co-author of several conference papers and patents. She serves on the CRA board of directors, and is the co-chair of CRA-Industry. She received the VLDB Women in Database Research Award in 2022. She is an ACM Fellow and the vice chair of ACM SIGMOD.
04/17 Jailbreaking Large Language Models - Weiliang Zhao, Columbia
- Readings
- Questions to ponder while reading. Discuss these at least one day BEFORE class!
- Can you think of a way to defend against these approaches?
- What evaluation criteria should be considered before a model is deployed?
04/22 Delivering knowledge to LLM inference engines via LMCache - Kuntai Du, UChicago
-
Toggle Bio
Kuntai Du is a 6th year PhD candidate from University of Chicago, advised by Professor Junchen Jiang. His research focuses on distributed tensor transmission for deep learning model serving systems. Beyond his academic work, he open-sources his research through LMCache and collaborates closely with Professor Ion Stoica and the UC Berkeley team to integrate it into the most popular LLM inference engine vLLM.
- Readings
- Questions to ponder
- Should LLMs continuously learn after deployment? If so, what would be a promising way?
04/24 Model Context Protocol - Elie Schoppik, Anthropic
-
Toggle Bio
Elie Schoppik leads live education at Anthropic as their Head of Technical Training. He has spent over a decade in technical education, working with multiple coding schools and starting one of his own. With a background in consulting, education, and software engineering, Elie brings a practical approach to teaching Software Engineering and AI. He's shared his insights at a variety of technical conferences as well as universities including MIT, Wharton, and UC Berkeley.
- Readings
- Questions to ponder
- Is there really a difference between MCP and A2A and (if so) what do you think it is?
What You Did
04/29 Presentations
05/01 Presentations
{kind=link}